# db.getCollection('dds_region').find({ "attrs.attrs.qymc": "全国"})MongoDB 基础
[TOC]
# 简介
- 存储文档的非关系型数据库
- 使用文档的好处是:
- 文档(即对象)对应于许多编程语言中的本机数据类型。
- 嵌入式文档和数组减少了对昂贵连接的需求。
- 动态模式支持流畅的多态性。
- 使用文档的好处是:
# 数据库结构
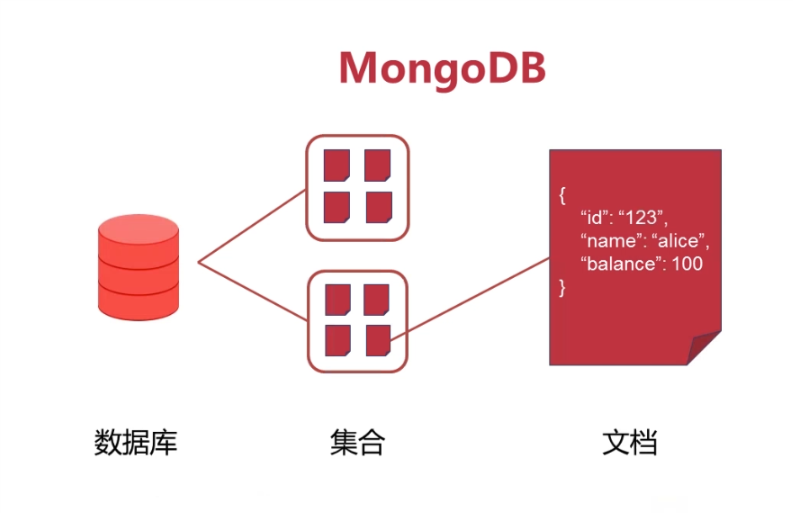
# 主要特点
高性能
MongoDB 提供高性能数据持久性。特别是,
- 对嵌入式数据模型的支持减少了数据库系统的 I / O 活动。
- 索引支持更快的查询,并且可以包含来自嵌入式文档和数组的键。
丰富的查询语言
MongoDB 支持丰富的查询语言以支持[读写操作(CRUD)以及:
- 数据聚合
- 文本搜索和地理空间查询。
高可用性
MongoDB 的复制工具称为副本集,它提供:
- 自动故障转移
- 数据冗余。
副本集是一组保持相同的数据集,从而提供冗余和提高数据可用性的 MongoDB 服务器。
水平可伸缩性
MongoDB 提供水平可伸缩性作为其核心 功能的一部分:
- 分片在一组计算机集群分布数据。
- 从 3.4 开始,MongoDB 支持基于分片键创建数据区域。在平衡群集中,MongoDB 仅将区域覆盖的读取和写入指向区域内的分片。
支持多个存储引擎
MongoDB 支持多个存储引擎:
- WiredTiger 存储引擎(包括对静态加密的支持 )
- 内存存储引擎
此外,MongoDB 提供可插拔存储引擎 API,允许第三方为 MongoDB 开发存储引擎。
# 使用 docker 容器运行 MongoDB
下载 MongoDB 的官方 docker 镜像
docker pull mongo:41查看下载的镜像
docker images1启动一个 MongoDB 服务器容器
docker run --name mymongo -v /mymongo/data:/data/db -d mongo:4 ##以后可以直接启动mymongo容器 docker start mymongo1
2
3查看 docker 容器状态
docker ps1查看数据库服务器日志
docker logs mymongo1
# Mongo Express
是一个基于网络的 MongoDB 数据库管理界面
下载 mongo-express 镜像
docker pull mongo-express1运行 mongo-express
docker run --link mymongo:mongo -p 8081:8081 mongo-express1访问数据库
localhost:80811
# mongo shell
mongo shell 是用来操作 MongoDB 的 JavaScript 客户端界面
运行 mongo shell
docker exec -it mymongo mongo1支持 JavaScript 语法
# 基本操作 CRUD
https://mws.mongodb.com/?version=4.0
文档主键_id
文档主键的唯一性
支持所有的数据类型(数组除外)
复合主键,(文档作为文档主键)
???文档作为主键时文档内容顺序是否影响文档的唯一性
默认对象主键 ObjectId
- 快速生成 12 字节的 id
包含创建时间
#获取创建时间 >ObjectId("5d5bd2854b18eb4e7922e52e").getTimestamp() ISODate("2019-08-20T10:59:17Z")1
2
3使用 mongo shell 操作数据库
use test #使用test数据库 show collections #查看数据库中的集合1
2
# C
# db.collection.insertOne()
插入集合一条数据
db.<collection>.insertOne( <document>, { writeConcern:<document> } )1
2
3
4
5
6- 不存在集合可自动创建集合
- writeConcren 文档定义了本次文档创建操作的安全写级别
- 安全写级别用来判断一次数据库写入操作是否成功
- 安全写级别越高,丢失风险就越低,然而写入操作的延迟可能就更高。
- 不提供该文档,mongoDB 使用默认的安全写级别
举例
将文档写入到 demo 集合中
db.demo.insertOne( { _id:"demo1", name:"zs", age:21 } )1
2
3
4
5
6
7
返回值
正确返回值
{ "acknowledged" : true, "insertedId" : "demo1" } #acknowledged:安全写级别是否被启动 #insertedId:文档主键1
2
3错误返回值
插入一条重复主键的文档,返回的信息较多,可以采用 try catch 方式进行定位异常
try{ db.demo.insertOne( { _id:"demo1", name:"zss", age:22 } ) }catch(e){ print(e) }1
2
3
4
5
6
7
8
9
10
11返回值:
WriteError({ "index" : 0, "code" : 11000, "errmsg" : "E11000 duplicate key error collection: test.demo index: _id_ dup key: { _id: \"demo1\" }", "op" : { "_id" : "demo1", "name" : "zss", "age" : 22 } })1
2
3
4
5
6
7
8
9
10
# db.collection.insertMany()
创建多个文档
db.<collection>.insertMany( [<document1>,<document2>,....], { writeConcren:<document>, ordered:<boolean> } )1
2
3
4
5
6
7- ordered 参数决定 mongoDB 是否要按顺序来写入这些文档
- 参数为 false,可以打乱文档的写入顺序,可以优化写入操作的性能
- 参数默认值为 true
- ordered 参数决定 mongoDB 是否要按顺序来写入这些文档
举例
db.demo.insertMany([ { name:"qq", age:12 }, { name:"ww", age:33 } ])1
2
3
4
5
6
7
8
9
10返回值
正确返回值
{ "acknowledged" : true, "insertedIds" : [ ObjectId("5d5bc9b94b18eb4e7922e526"), ObjectId("5d5bc9b94b18eb4e7922e527") ] }1
2
3
4
5
6
7错误返回值
其中一条带有重复主键
try{ db.demo.insertMany([ { _id:"demo1", name:"qq", age:12 }, { name:"ww", age:33 } ]) }catch(e){ print(e) }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15返回:
BulkWriteError({ "writeErrors" : [ { "index" : 0, "code" : 11000, "errmsg" : "E11000 duplicate key error collection: test.demo index: _id_ dup key: { _id: \"demo1\" }", "op" : { "_id" : "demo1", "name" : "qq", "age" : 12 } } ], "writeConcernErrors" : [ ], "nInserted" : 0, "nUpserted" : 0, "nMatched" : 0, "nModified" : 0, "nRemoved" : 0, "upserted" : [ ] })1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22nInserted 代表成功插入的条数
???正序插入和乱序插入的成功插入条数一样嘛
???正序插入后面文档出错,前面文档会被写入嘛
# db.collection.insert()
创建单个或多个文档
db.<collection>.insert( <document or array of document>, { writeConcren:<document>, ordered:<boolean> } )1
2
3
4
5
6
7返回值
正确返回,
返回成功写入文档的数量等等
WriteResult({"nInserted":1})1错误返回
和上个类似
# db.collection.save()
- db.collection.save 命令处理一个新文档的时候,他会调用 db.collection.insert()命令
- 举例返回结果文档和 db.collection.insert()命令相同
- 区别
- 新增的数据中已存在主键,则再次插入相同的主键时 insert() 会提示错误,而 save() 则更改原来的内容为新内容。
- insert 可以一次性插入一个列表,而不用遍历,效率高, save 则需要遍历列表,一个个插入。
# 区别
- 返回数据信息不同
- insertOne 和 insertMany 命令不支持 db.collection.explain()命令
- insert 支持 db.collection.explain()命令
# R
# db.collection.find()
结构
db.<collection>.find(<query>,<projection>)1文档定义了读取操作时筛选文档的条件 文档定义了对读取结果进行的投射
读取全部文档
db.collection.find() db.collection.find().pretty() #更清晰的显示文档1
2
# 匹配查询
读取 zs 的个人信息
db.demo.find({name:"zs"})1返回
{ "_id" : ObjectId("5d5bc9b94b18eb4e7922e526"), "name" : "zs", "age" : 12 }1
可以匹配多个条件
db.demo.find({name:"zs",age:12})1匹配复合主键时,可以直接_id.复合主键的字段。
_id.***:"内容" ###***代表复合主键中的某一字段1
# 比较操作符
{ <filed>: { $<operator>:<value> } }
$eq 匹配字段值相等的文档
$ne 匹配字段值不等的文档
注:会筛选出并不包含查询字段的文档(匹配 age 不等于 18,没有 age 这个字段的文档也会匹配出来)
$gt 匹配字段值大于查询值的文档
$gte 匹配字段值大于或等于查询值的文档
$lt 匹配字段值小于查询值的文档
$lte 匹配字段值小于或等于查询值的文档
举例
读取 zs 的个人信息
db.demo.find({name: {$eq: "zs" } })1读取不属于 zs 的个人信息
db.demo.find({name: {$ne: "zs" } })1读取年龄大于 18 的个人信息
db.demo.find({age: {$gt: 18 } })1
$in 匹配字段值与任意查询值相等的文档
{field: { $in:[<value1>,<value2>....] } }1读取 zs 和 ww 的个人信息
db.demo.find({name: {$in: ["zs","ww"] } })1
$nin 匹配字段值与任何查询值都不相等的文档
- 读取除了 zs 和 ww 的个人信息
# 逻辑操作符
$not
{ <filed>: { $not :{ <operator-expression> } } }1读取年龄不小于 18 的个人信息
db.demo.find({ age: { $not :{$lt: 18} } } )1
$and
{ $and :[ {<expression1>},{<expression2>,......} ] }1读取年龄大于 18 并且用户姓名排在 zs 之后的用户文档
db.demo.find({ $and: [ { age: { $gt:18 } }, { name: { $gt:"zs" } } ] } )1
2
3
4
5
6当筛选条件应用在不同字段上时,可以省略$and 操作符
db.demo.find({ age: { $gt:18 } , name: { $gt:"zs" } } )1
2
3
4当筛选条件应用在同一字段上时,也可以省略$and 操作符
读取年龄大于 18 并且小于 30 的个人信息文档
db.demo.find({ age: { $gt:18 ,$lt:30} } )1
2
3
$or
{ $or :[ {<expression1>},{<expression2>,......} ] }1- 读取 zs 或者 ww 的个人信息文档
- 不可省略
$nor
{ $nor :[ {<expression1>},{<expression2>,......} ] }1读取不属于 zs 和 ww 并且年龄不小于 18 的个人信息文档
db.demo.find({ $nor: [ { name:"zs" }, { name:"ww" }, { age: { $lt:18 } } ] } )1
2
3
4
5
6
7$nor 也会筛选出并不包含查询字段的文档
# 字段操作符
$exists 匹配包含查询字段的文档(可以解决 ne 和 nor 精确匹配问题)
{field: { $exists :<boolean> } }1读取包含电话字段的个人信息文档
db.demo.find( { phone: { $exists :true } } )1可以解决 ne 和 nor 精确匹配问题
db.demo.find({name: {$ne: "zs" ,$exists :true} })1
$type 匹配字段类型符合查询值的文档
{field: { $type: <BSON type> } } {field: { $type: [<BSON type1>,<BSON type2>.....]} }1
2读取文档主键是字符串的文档主键
db.demo.find( { _id: { $type :"string" } } )1读取用户姓名是 null 的银行账户文档
db.demo.find( { name: { $type :"null" } } )1使用对应的 BSON 类型序号作为$type 操作符和参数
db.demo.find( { _id: { $type :2 } } #2代表字符串1
# 数组操作符
$all 匹配数组字段中包含所有查询值的文档
{ <field>: { $all: [ <value1>, <value2>.....] } }1db.getCollection('dds_region').find({ "attrs.attrs.qymc": "全国"})1
$elemMatch 匹配数组字段中至少存在一个值满足筛选条件的文档
{ <field>: { $elemMatch : [ <query1>, <query2>.....] } }1
# 运算操作符
regex 匹配满足正则表达式的文档
{ <field>: { : /pattern/, :'<options>' } } #常用1{ <field>: { : /pattern/<options> } } #和$in一起1在和$in 操作符一起使用的时,只能使用第二种
读取用户姓名以 c 开头或者 j 开头的用户文档
db.demo.find({ name:{$in: [ /^c/, /^j/ ] } } )1读取用户姓名包含 LIE(不区分大小写)的用户文档
db.demo.find( name: { $regex:/LIE/, $options:'i' } )1
# 文档游标
db.collection.find() 返回的一个文档集合游标
在不迭代游标的情况下,只列出前 20 个文档
我们可以使用游标下标直接访问文档集合中某一个文档
>var myCursor = db.demo.find() myCursor[1]1
2游历完游标中所有的文档之后,或者在 10 分钟之后,游标会自动关闭
可以使用 noCursorTimeout()函数来保持游标一直有效
>var myCursor = db.demo.find().noCursorTimeout()1在这之后,在不遍历游标的情况之后,你需要主动关闭游标
myCursor.close()1
游标函数
- cursor.hasNext() 是否有下一个文档
- cursor.Next() 指向下一个文档
- cursor.forEach()
- cursor.limit()
- 传入数字,只返回多少文档
- ????limit(0) 不使用
- cursor.skip()
- 传入数字,跳过多少文档
- 永远在 limit()之前执行
- cursor.count()
- cursor.sort()
- 永远在 skip()和 limit()函数之前执行
>var myCursor = db.demo.find({name:"zs"}); while(myCursor.hasNext()){ printjson(myCursor.next()); }1
2
3
4
# 文档投影
db.collection.find(<query>,<projection>)
不使用投影时,返回完整的文档信息
使用文档时,可以有选择性的返回文档中的部分字段
{filed: inclusion }11 表示返回的字段,0 表示不返回的字段
只返回用户文档中的用户姓名
db.demo.find( {}, { name:1 } )1只返回用户文档中的用户姓名(不包含文档主键)
db.demo.find( {}, { name:1, _id: 0 } )1
除了文档主键之外,我们不可以在投影文档中混合使用包含和不包含这两种投影操作
- 要么列出所有应该包含的字段,要么列出所有不应该包含的字段,不然会报错。
在数组字段上使用投影
$slice 操作符可以返回数组字段中的部分元素
db.demo.find( {}, { _id: 0, name:1, contact:{$slice: 1} } )1contact 数组字段只返回第一个元素
-1 代表返回最后一个
[1,2]跳过第一个元素,返回之后 的两个元素
也可以使用$eleMatch 对数组字段进行筛选
如果 find 的筛选条件和数组内字段的筛选条件相同可以直接使用数组字段.$
db.demo.find( {contact:{$gt: "zs"}}, { _id: 0, name: 1, "contact.$": 1 } } )1
2
3
4
# U
# db.collection.update()
db.<collection>.update(<query>, <update>, <options>)
##<query>文档定义筛选条件和.find()条件相同
##<update>文档定义了做什么样的更新
##<options>文档声明了一些更新操作的参数
2
3
4
5
# 整篇更新文档
里提供整篇文档
举例
查询 zs 的个人信息
>db.demo.find({ name: "zs" } ) { "_id" : "demo1", "name" : "zs", "age" : 21 }1
2将 zs 的年龄改为 23
>db.demo.update( { name: "zs"}, { name: "zs", age: 23} ) WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 }) ##nMatched" : 1 代表有一个符合查询的结果 ##nModified" : 1 代表有一个完成更新1
2
3
4
文档主键_id 是不可以更改的
在使用
文档替换整篇被更新的文档时,只有第一篇符合 文档筛选条件的文档才会被更新 - 假如整篇更新年龄大于 18 少于 20 的文档,如果有两篇,但也只会更新第一篇
更新整篇文档只能应用于单一文档上
# 更新特定字段
如果
文档只包含更新操作符,update 将会更新集合中符合筛选条件的特定字段
文档更新操作符
$set 更新或者新增字段
{ $set: { <filed1>: <value1>,..... } }1更新 ww 的年龄和增加其他信息
db.demo.update( { name: "ww" }, { $set: { age: 24, info: { createTime: new Date("2016-05-18T16:00Z"), branch: "branch1" }, } } )1
2
3
4
5
6
7
8
9
10
11
12内嵌文档更新
$set:{ "info.branch":"new branch" }1
2
3数组内字段更新
$set:{ "contact.3":"new contact" }1
2
3- 如果下标跳过原长度进行更新,也会更新成功,中间未被赋值用 null 进行补充
$unset 删除字段
db.demo.update( { name: "ww" }, { $unset: { age: "", "info.branch" : "", } } )1
2
3
4
5
6
7
8
9- age:""引号内可以填写任何内容,都会被删除
- 删除数组元素时,长度不会被改变,被删除的位置会变为 null
$rename 重命名字段
{ $rename: {<filed1>: <newName1>, <filed2>: <newName2>...}}1如果新的字段名已经存在,那么原有的这个字段会被覆盖
db.demo.update( { name: "qq" }, { $rename: { "age": "name" } } ) #原先的name会被覆盖掉,现在的name等于以前的age值1
2
3
4
5
6
7
8
9可以将内嵌文档和外层的文档移动位置,,数组不可以
$inc 加减字段值
$mul 相乘字段值
{ $inc: { <filed1>: <amount1>,.....}} { $mul: { <filed1>: <amount1>,.....}}1
2更新 zs 的年龄
db.demo.update( { name: "zs" }, { $inc: { age:-1 } } )1
2
3
4
5
6
7
8两种运算操作符只能操作数字类型字段
如果被操作的字段不存在时
- $inc 会创建字段,并将字段值设置为命令中的增减值
- $mul 会创建字段,但是字段值会设为 0
$min 比较保留最小的字段值
$max 比较保留最大的字段值
{ $min: { <filed1>: <value1>,.....}} { $max: { <filed1>: <value1>,.....}}1
2db.demo.update( { name: "zs" }, { $min: { age:18 } } ) #age比18大就更新为18,保留最小的值1
2
3
4
5
6
7
8
9如果更新字段不存在,两种命令会创建该字段,并且将该字段值设为命令中的更新值
如果被更新字段类型和更新值类型不一致,命令会按照 BSON 数据类型的排序规则进行比较
#最小 Null Numbers (ints, longs, doubles) Symbol, String Object Array BinData ObjectID Boolean Date, Timestamp #最大1
2
3
4
5
6
7
8
9
10
11
# 数组更新操作符
$addToSet 向数组中增添元素
{ $addToSet: { <filed1>: <value1>,.....}}1添加文档数组中的元素
db.demo.update( { name: "zs" }, { $addToSet: {contact: "China"} } ) #contact为文档中的数组元素,为该数组添加一个元素1
2
3
4
5如果数组中已经存在,不会进行更新
- 如果数组中存在内嵌文档,内嵌文档中的元素顺序和内容完全一样才算已存在
将数组插入被更新的数组中,会成为内嵌数组
如果想将数组中元素,直接插入到数组中可以使用$each 操作符
db.demo.update( { name: "zs" }, { $addToSet: {contact: {$each: ["contact1","contact2"] } } } ) ###contact1和contact2会直接插入到contact数组中,不会成为内嵌数组1
2
3
4
5
$pop 从数组中移除元素
{ $pop : { <filed1>: <-1 | 1>,.....} } #最后1,开始-11只能删除第一个或者最后一个元素
删除数组字段中最后一个元素
db.demo.update( { name: "zs" }, { $pop: {contact: 1} } )1
2
3
4如果数组元素都被删除,空数组也会被保留下来
$pull 从数组中有选择性的移除元素
{ $pull: { <filed1>: <value | condition>,.....} }1可以删除特定位置的数组
删除一数组字段中包含“hi”字母的元素
db.demo.update( { name: "zs" }, { $pull: { contact: { $regex: /hi/ } } } )1
2
3
4匹配内嵌数组元素时,可以使用$elemMatch 操作符进行匹配
删除内嵌文档时,只要部分字段匹配,即可删除该内嵌文档,只要形成包含关系,顺序也无关
$pullAll 从数组中有选择性的移除元素
{ $pullAll: { <filed1>: [<value1>,<value2>...],.....} }1- 参数为一个数组,可以删除多个元素
- 删除内嵌文档时,必须顺序和内容完全一样
$push 向数组中增添元素
{ $push: { <filed1>: <value1>,.....}}1可以添加重复元素
可以和$each 搭配使用
可以和$position 操作符搭配使用,从当前位置开始操作
>db.collection.update( { name: "lawrence" }, { $push:{ "newArray": { $each: ["pos1", "pos2"], $position: 0 } } } )1
2
3
4
5
6
7
8
9
10可以和$sort 操作符搭配使用,一定要搭配 push 和 each 操作符使用
>db.collection.update( { name: "lawrence" }, { $push:{ "newArray": { $each: ["sort"], $sort: 1 } } } )1
2
3
4
5
6
7
8
9
10插入之后排序,sort 的值为 1 时为正序排序,-1 为倒序排序
有内嵌文档时,可以指定字段进行排序
$sort: {value: 1}1不插入元素,只进行排序
>db.collection.update( { name: "lawrence" }, { $push:{ "newArray": { $each: [], $sort: 1 } } } )1
2
3
4
5
6
7
8
9
10
可以搭配$slice 来截取部分数组,一定要搭配 push 和 each 操作符使用
插入元素之后,截取数组后八位元素
>db.collection.update( { name: "lawrence" }, { $push:{ "newArray": { $each: ["slice1"], $slice: -8 } } } )1
2
3
4
5
6
7
8
9
10
position,sort,slice 操作符可以一起使用
- 执行顺序为 position,sort,slice
- 写命令的顺序,并不影响命令的执行顺序
数组占位符
$
db.collection.update( { <array>: <query selector> }, { <upadate operator>: {"<array>.$": value } } )1
2
3
4在有数组筛选条件而不确定数组下标的时候,可以使用$占位符
$是数组中第一个符合筛选条件的数组元素的占位符
举例
{ "name" : "ww", "newArray" : [ "push1", "push2", "push3" ] } >db.collection.update( { name: "lawrence", newArray: "push3" }, { $set:{ "newArray.$": "updated" } } ) ###可以将数组中的push3更新为updated1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
$[]
{ <upadate operator>: {"<array>.$[]": value } }1- 更新数组中所有元素
- $[]指代数组字段中所有元素
# options 选项
{multi: <boolean> }1更新多个文档
update 命令使用的筛选条件只对应于一篇文档,
在默认情况下,即使筛选条件对应了多篇文档,update 命令仍然只会更新第一篇文档
db.demo.update( {}, #匹配所有文档 { $set: { currency: "USD" }, } {mulit: true } #不加该选项则只会更新第一篇文档 )1
2
3
4
5
6
7
8更新多个文档操作不能保证其文档的原子性,更新多个文档时中途可能被其他线程挂起,以防止一个进程霸占数据库资源,
- 如果要保证,需要引入 mongodb4.0 版本的事务功能
{upsert: <boolean> }1- 更新或者创建文档
- 在默认情况下,如果 update 命令中筛选条件没有匹配任何文档,则不会进行任何操作
- upsert 为 true 时,如果 update 命令中的筛选条件没有匹配任何文档,则会创建新文档
- 如果无法从筛选条件中推断出确定的字段值,新创建的文档将不会包含筛选条件涉及的字段,比如筛选条件是一个不等式
# db.collection.findAndModify()
db.<collection>.findAndModify(<docunment>)
- 方法用于修改和返回单个文档。默认情况下,返回的文档不包括对更新所做的修改。
# db.collection.save()
db.<collection>.save(<docunment>)
- 如果 document 文档中包含了_id 子弹,save()命令将会调用 db.collection.update() 命令 ,并且(upsert: true)
# D
# db.collection.remove()
db.<collection>.remove(<query>,<options>)
删除特定文档
删除年龄为 18 的个人信息
>db.demo.remove({age: 18}) WriteResult({ "nRemoved" : 1 })1
2默认情况下,删除所有筛选条件 文档
如果指向删除第一项符合筛选条件的文档可以使用 justOne 选项
删除集合内所有文档
db.demo.remove({})1
# db.collection.drop()
db.<collection>.drop( { writeConcern: <document> } )
#writeConcern定义了本次集合删除操作的安全写级别,可省略为默认
2
- 删除整个集合,包含所有集合,以及集合的索引
- 效率较高